README 教你用 Kit;這篇講 Kit 放在哪一層。
如果你只是想知道 Agent Handoff Kit 怎樣安裝、怎樣開工、怎樣收工,README、60 秒 intro 和實操 guide 已經足夠。這篇不應重複那些內容。
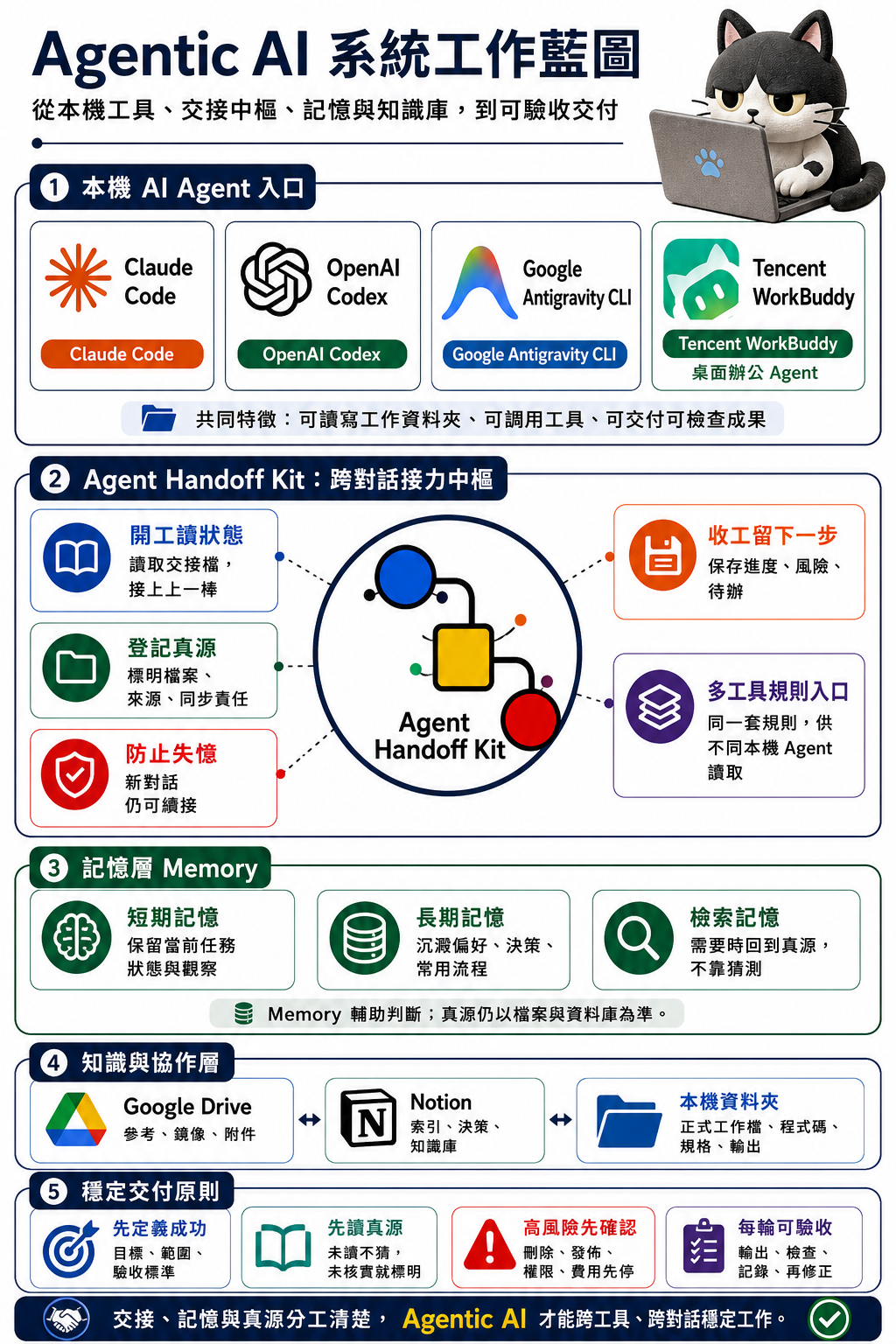
這篇真正要補上的,是一個架構層問題:當你開始使用 Claude Code、OpenAI Codex、Google Antigravity CLI、Tencent WorkBuddy 這類本機 AI Agent 時,整套工作方法應該怎樣分層,才不會每次開新對話都重新入職、重新解釋、重新混亂。
所以,Agent Handoff Kit 在這篇不是主角,不是平台,不是記憶資料庫,也不是 Notion 或 Google Drive 同步工具。它是整套本機 Agentic AI 工作系統中的「項目連續性與交接層」:把開工入口、目前狀態、下一步、風險、真源登記、規則入口、安全邊界和收工提示放進項目文件。正因為只佔這一層,它的定位才清楚。